[TIL] pyspark(3) - 파이스파크로 데이터 불러오기, 데이터 프레임 수정, 데이터 요약하기
오늘은 저번에 이어 본격적으로 세션을 만들고 데이터를 불러오고, 조작하는 여러 예제를 실습해보았다.

스파크 세션이란?
파이스파크에서 스파크 데이터셋 및 데이터 프래임을 프로그래밍하기 위해서는 이 스파크 세션을 빌드해주어야 한다.
공식문서에서는 스파크 세션의 쓰임을 아래와 같이 언급한다.
A SparkSession can be used create DataFrame, register DataFrame as tables, execute SQL over tables, cache tables, and read parquet files.
스파크 세션은 내부적으로 마스터 노드인 SparkContext와 상호작용한다. SparkContext는 클러스터 내의 작업반장과 같은 역할을 하는데, Cluster내의 각 노드에 task를 할당하고 조정한다. 어찌되었든 스파크에서 어떠한 작업을 하려면 스파크 세션은 빌드하고 시작해야한다는 의미이다.
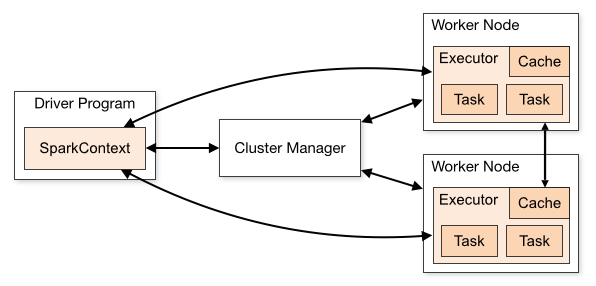
파이스파크에서 데이터 불러오기
그럼 본격적으로 데이터를 불러와보겠다. 필자는 데이터는 기존에 가지고 있던 주문 데이터(99442 rows)를 사용하였다.
아래 코드는 스파크 세션을 먼저 빌드한 후 주문 데이터셋의 첫 10개의 열을 불러온다.
# 스파크 데이터를 불러오는 예제
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('test').getOrCreate() # initiates a spark session
# Loading Data
path = r'C:\Users\*********\Documents\practice\Dataset\orders_dataset.csv'
df = spark.read.csv(path)
print(f'# of rows : {df.count()}\n')
df.show(10) # print를 하지 않아도 출력된다.

csv 파일을 열 때는 판다스 데이터 프레임처럼 header 옵션이나 null값을 어떤식으로 처리할 지 설정할 수 있다.
아래는 header 값을 true로 한 경우이다.
df = spark.read.option('header','true').csv(path) # csv 메서드에 nullValue='NA'전달 가능
df.show(10)위 코드의 결과값은 다음과 같다.

데이터 타입 출력하기
데이터를 불러왔으면 데이터 타입을 확인할 차례이다. 데이터 타입은 두가지 방법으로 확인할 수 있다. 각각의 출력값이 조금씩 다르므로 상황에 맞게 활용하면 좋을 듯 싶다.
df.printSchema() # Prints data types and null constrains
print(df.dtypes) # Returns a list of (column, data type) tuple

컬럼 수정하기
데이터 타입을 확인했더니 날짜형 데이터도 모두 string 타입으로 지정되어있다. 이럴 때 `withColumn` 커맨드를 이용하여 컬럼의 데이터 타입을 수정할 수 있다.
데이터 타입 변경하기
원하는 타입을 import 해온 후 `withColumn` 커멘드 내 cast 함수를 이용하여 변경한다.
from pyspark.sql.types import DateType # Import a data type you want to transform into
# Before transformation
df.printSchema()
# After
df = df.withColumn('order_approved_at', df.order_approved_at.cast(DateType()))
df.printSchema()Output :


컬럼명 변경하기
`withColumnRenamed()` 함수를 이용하면 컬럼 이름도 변경할 수 있다.
# After renaming
df = df.withColumnRenamed('order_approved_at', '주문확인일자')
df.printSchema()
여러개의 컬럼명을 변경할 때는 for문을 사용하여 인자값을 전달해준다.
기술통계량 확인하기
판다스에서도 데이터를 확인할 때 가장 먼저 확인하는 것은 당연 기술 통계량을 확인하는 것이다. 원래 사용하던 주문 데이터에는 숫치형 변수가 없어 이번에는 결제 데이터셋을 이용하였다. 먼저 string으로 설정되어있는 컬럼을 정수형, 실수형으로 변경해주고 `df.select()`로 기술통계량을 확인했다.
# Dataset의 요약 통계량을 확인하는 예제
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('test').getOrCreate() # initiates a spark session
# Loading Data
path = r'C:\Users\********\Documents\practice\Dataset\order_payments_dataset.csv'
df = spark.read.option('header','true').csv(path)
df.show(3)
df.printSchema()
# Transform column types
from pyspark.sql.types import FloatType, IntegerType
df = df.withColumn('payment_installments', df.payment_installments.cast(IntegerType())) # 원래는 숫자형이면 안되지만 편의상 Int타입으로 변경한다.
df = df.withColumn('payment_value', df.payment_value.cast(FloatType()))
# Describe dataset
df.select(['payment_installments', 'payment_value']).describe().show()그 결과 string으로 설정되어있는 나머지 컬럼들은 제외하고 수치형 컬럼들에 대해서만 요약통계량이 출력된다. (참고로 날짜 데이터도 요약통계량을 보여주지 않는다.)

참고
[Youtube] 스파크 튜토리얼
[사진출처] 스파크 공식문서
https://spark.apache.org/docs/latest/cluster-overview.html
스파크 데이터타입