[토이프로젝트] Ecommerce 비즈니스 성과 분석하기 (Feat.SQL) (3)
이 프로젝트는 미디엄의 'Project Data Analysis : Analyzing E-Commerce Business Performance (By M. Hamzah)'를 참고하여 진행했다. 원문 전체를 번역한 것이 아닌, 공부하다가 필요한 부분을 정리한 것이다.
2편 : ERD 및 데이터 구조 살펴보기 바로가기
[토이프로젝트] Ecommerce 비즈니스 성과 분석하기 (Feat.SQL) (2)
이 프로젝트는 미디엄의 'Project Data Analysis : Analyzing E-Commerce Business Performance'를 참고하여 진행했다. 원문 전체를 번역한 것이 아닌, 공부하다가 필요한 부분을 정리한 것으로 원문은 하단에 링크
iwannatakeabreakfromschool.tistory.com
저번 편에서는 원문에서 보여준 ERD를 참고하여 FK, PK을 지정하려 시도해보았으나, 알고보니 ERD는 논리적 스키마였고 실제 물리적으로는 동작하지 않는 관계로 설정이 되어있었다.
당시 나는 SQLD를 공부하기 이전이었는데, 이전에는 DB를 설계할 때 반드시 테이블 간 관계를 설정해주어야 하는 줄 알았지만, FK나 PK와 같은 제약조건은 데이터 무결성을 유지하기 위해 DBMS에서 제공하는 하나의 기능이라는 것을 깨닳게 되었다. (CASCADE 같은 기능으로 부모 테이블에서 레코드 값 삭제 시 다른 참조 테이블의 해당 값도 삭제하는 등 유용한 기능이 있으나...이번 프로젝트에서는 결국 설정 안해도 데이터 분석에는 크게 문제가 없다는 의미)
그래서 이번 편에서는 본격적으로 분석을 진행해본다.
주요 분석 과제
1. 2016~2018년도 기간 내 전체적인 고객 활동 그로스(Growth) 확인 : 월간 활성 사용자 수(MAU), 신규고객, 재구매고객, 고객 당 평균 주문건
2. 동 기간 내 전체적인 제품 카테고리 품질 : 총 수입(Total revenue), 총 취소 주문 건, 베스트 셀링 제품 카테고리와 가장 많이 취소된 카테고리
3. 동 기간 내 전체적인 결제 타입 별 수단 : 전체 기간 가장 선호되는 결제 수단 , 연도 별 각 결제 타입 별 수단
1. 연간 고객 활동 그로스(Growth) 분석
SQL 쿼리 짜는 연습도 할 겸 쿼리는 직접 작성 후 틀린점이 있는 경우 원본을 참고했다.
1) 연간 평균 MAU
여기서는 구매 고객 수를 Active User로 가정했다. 원 데이터에 유저 행동 데이터가 없어 이런 Strict한 기준으로 잡은 듯 하다. 이 경우 사실상 MAU라기보다는 그냥 월 평균 구매 고객 수와 다름없다고 생각한다. (참고로 Active user의 정의는 산업별, 서비스 별로 접속빈도 기준, 측정 방법 등이 다르다. GA4에서 MAU, DAU 등을 계산하기 위한 활성 사용자는 그냥 사용자 행동 데이터의 session_id 개수를 세어 계산한다고 한다.)
SELECT y year, ROUND(sum(MAU)/count(m)) avg_mau
FROM (
SELECT YEAR(order_purchase_timestamp) y
, MONTH(order_purchase_timestamp) m
, COUNT(DISTINCT cd.customer_unique_id) MAU
FROM orders_dataset od
LEFT JOIN customers_dataset cd
ON od.customer_id = cd.customer_id
GROUP BY y,m
) c
GROUP BY y;먼저 서브쿼리에서 연도별, 월 별로 MAU를 구한다. 그 후 메인쿼리에서 연도별 MAU를 집계한다. 원문에서는 `DATE_PART()` 함수를 이용했는데 나는 MySQL을 이용했기에 MONTH(), YEAR() 함수를 사용하여 년, 월을 추출했다.
결과 :

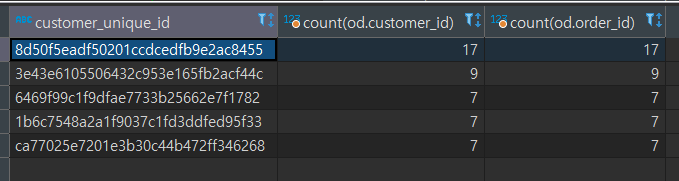
여기서 살짝 햇깔렸던 부분은 customers 테이블의 `customer_id`와 `customer_unique_id`였는데 그냥 id는 주문 별로 다르게 생성되어 한 고객이 4개의 주문을 했다면 4개의 id 값을 가질 수 있다. unique_id의 경우 Not null의 진짜 고객 식별자이다. 아래 결과를 보면 주문자 별로 customer_id 집계 건 수와 주문 번호 집계 건 수가 동일한 것을 알 수 있다.
따라서 고객 수 집계시 unique_id를 기준으로 삼아야 한다.
2) 연도별 신규 고객의 수
나는 원문과 다르게 주문을 취소한 고객 혹은 주문이 불가한 고객은 신규 고객으로 간주하지 않았다.
서브쿼리에서 먼저 신규 고객을 구한 후 메인쿼리에서는 연도별로 집계한다.
SELECT
YEAR(first_order) AS `year`, COUNT(customer_unique_id) AS `number of new customers`
FROM (
SELECT
cd.customer_unique_id,
MIN(od.order_purchase_timestamp) AS 'first_order'
FROM
orders_dataset od
INNER JOIN
customers_dataset cd
ON
od.customer_id = cd.customer_id
WHERE -- 주문을 취소하거나 주문이 불가한 고객은 제외
od.order_status NOT IN('unavailable','canceled')
GROUP BY
cd.customer_unique_id
) AS sub
GROUP BY YEAR(first_order)
ORDER BY 1;
결과 :

3) 연도별 재구매 고객의 수
이번에는 재구매 고객의 수 이므로 서브쿼리에서 연간 주문 건 수가 1을 초과하는 건 만 조회하도록 HAVING을 사용한다.
SELECT year, COUNT(total_customers) AS `Number of repeat customers`
FROM (
SELECT
YEAR(od.order_purchase_timestamp) AS year,
cd.customer_unique_id,
COUNT(od.order_id) AS total_customers
FROM
orders_dataset od
INNER JOIN
customers_dataset cd
ON
od.customer_id = cd.customer_id
WHERE -- 주문을 취소하거나 주문이 불가한 고객은 제외
od.order_status NOT IN('unavailable','canceled')
GROUP BY
YEAR(od.order_purchase_timestamp), cd.customer_unique_id
HAVING
COUNT(od.order_id) >1
) sub
GROUP BY 1
ORDER BY 1;결과 :

4) 연간 구매 빈도 추이
서브쿼리에서는 연간 고객별 주문 건 수를 구한 뒤 메인쿼리에서는 연도별 고객들의 주문 빈도를 구한다.
SELECT
year, ROUND(AVG(total_customers), 2) AS avg_frequency_order
FROM (
SELECT
YEAR(od.order_purchase_timestamp) AS year,
cd.customer_unique_id,
COUNT(od.order_id) AS total_customers
FROM
orders_dataset od
INNER JOIN
customers_dataset cd
ON
od.customer_id = cd.customer_id
WHERE -- 주문을 취소하거나 주문이 불가한 고객은 제외
od.order_status NOT IN('unavailable','canceled')
GROUP BY
YEAR(od.order_purchase_timestamp), cd.customer_unique_id
) sub
GROUP BY 1;결과 :

5) 이제 위에서 구한 결과들을 CTE(Common Table Expression)에 통합하여 생성한다.
무려 90의 쿼리가 완성되었다...
원문에서 with 구문으로 테이블을 생성하는 이유는 결과들을 통합해서 확인하고 시각화하기 위한 것을 추측된다.
다른 자료를 찾아보니 실무에서도 JOIN 문의 가독성, 간소화를 위해 with 구문을 사용하는 경우가 있다고 한다.
WITH count_mau AS (
SELECT y year, ROUND(sum(MAU)/count(m)) Avg_mau
FROM (
SELECT YEAR(order_purchase_timestamp) y
, MONTH(order_purchase_timestamp) m
, COUNT(DISTINCT cd.customer_unique_id) MAU
FROM orders_dataset od
LEFT JOIN customers_dataset cd
ON od.customer_id = cd.customer_id
GROUP BY y,m
) c
GROUP BY y
),
count_new_customer AS (
SELECT
YEAR(first_order) AS `year`, COUNT(customer_unique_id) AS `Number of new customers`
FROM (
SELECT
cd.customer_unique_id,
MIN(od.order_purchase_timestamp) AS 'first_order'
FROM
orders_dataset od
INNER JOIN
customers_dataset cd
ON
od.customer_id = cd.customer_id
WHERE -- 주문을 취소하거나 주문이 불가한 고객은 제외
od.order_status NOT IN('unavailable','canceled')
GROUP BY
cd.customer_unique_id
) AS sub
GROUP BY YEAR(first_order)
ORDER BY 1
),
count_repeat_customer AS (
SELECT year, COUNT(total_customers) AS `Number of repeat customers`
FROM (
SELECT
YEAR(od.order_purchase_timestamp) AS year,
cd.customer_unique_id,
COUNT(od.order_id) AS total_customers
FROM
orders_dataset od
INNER JOIN
customers_dataset cd
ON
od.customer_id = cd.customer_id
WHERE -- 주문을 취소하거나 주문이 불가한 고객은 제외
od.order_status NOT IN('unavailable','canceled')
GROUP BY
YEAR(od.order_purchase_timestamp), cd.customer_unique_id
HAVING
COUNT(od.order_id) >1
) sub
GROUP BY 1
ORDER BY 1
),
avg_order AS (
SELECT
year,
ROUND(AVG(total_customers), 2) AS Avg_frequency_order
FROM (
SELECT
YEAR(od.order_purchase_timestamp) AS year,
cd.customer_unique_id,
COUNT(od.order_id) AS total_customers
FROM
orders_dataset od
INNER JOIN
customers_dataset cd
ON
od.customer_id = cd.customer_id
WHERE -- 주문을 취소하거나 주문이 불가한 고객은 제외
od.order_status NOT IN('unavailable','canceled')
GROUP BY
YEAR(od.order_purchase_timestamp), cd.customer_unique_id
) sub
GROUP BY 1
)
SELECT
cm.year AS 'Year',
cm.Avg_mau,
cn.`Number of new customers`,
cr.`Number of repeat customers`,
ao.Avg_frequency_order
FROM
count_mau cm
JOIN
count_new_customer cn ON cm.year = cn.year
JOIN
count_repeat_customer cr ON cm.year = cr.year
JOIN
avg_order ao ON cm.year = ao.year;결과 :

2. 결과 해석 및 시각화
시각화는 테블로를 사용했다.

원문에서는 위와 같이 연간 평균 MAU와 연간 전체 신규 고객 수를 연간 추이로 같은 그래프 상에 두고 다음과 같이 분석했다.
- 2017년은 의미있는 성장을 보였다. 2016년의 데이터는 9월 초부터 시작하여 4개월간의 데이터밖에 없기 때문이다. 이에 따라, 2017년에는 증가만 있었을 것으로 결론지을 수 있다.
- 같은 기간, MAU의 추세 또한 매년 증가하여 5,338명에 도달했다.

- 2017년도에서 2018년도에는 2회 이상 재구매고객의 수에 증가하는 경향이 있다.그러나 2018년에는 조금의 감소가 있었다.
- 고객의 평균 주문 건 수는 각 해마다 크게 달라지지 않았다. 일반적인 고객은 평균적으로 오직 1번만 제품을 구매한다.
여기까지는 원문의 결과 해석이다. 그러나 내 생각에 위의 분석에는 몇가지 한계점이 있어보인다.
- 먼저, 데이터 기간은 2016년 9월~2018년 10월까지의 데이터이기 때문에 각 해의 연간 합산 지표에 대해 비교하는 것은 적절하지 못하다고 생각한다. 만약 사업의 성장적 측면에서 분석을 진행하고자 했다면 연간지표가 아닌 분기별 혹은 반기별 지표 결산을 분석하는 것이 더 유의미하지 않았을까 하는 아쉬움이 남는다.
- 두 번째로, 위의 분석은 '사업이 성장했나보다...' 를 제외한 큰 인사이트를 주지 못한다고 생각한다. 바로 행동으로 이어질 수 있을만한 분석 결과가 있어야 구성원을 움직일 수 있다.
위의 아쉬움을 뒤로 하고 이 토이 프로젝트는 여기서 마무리하고자 한다. 다른 사람의 분석 프로젝트를 직접 재현해보면서 With문으로 임시테이블을 만드는 방법을 배울 수 있었고, PK와 FK 제약사항과 논리적스키마와 물리적 스키마에 대해서도 공부해볼 수 있었다. 또한, 이 원문의 분석 결과를 해석해보면서 여러 한계들을 발견했고 나는 다음 분석 프로젝트를 진행할 때, 이 부분을 참고해서 진행해야겠다.
린분석을 안보고 이 프로젝트를 봤으면 무비판적으로 수용했을텐데 책이 도움이 많이 되었다. ㅎㅎ... 아무튼 이번 프로젝트는 여기까지!
참고
활성사용자의 정의
https://datarian.io/blog/active-users-with-ga4-bigquery#480cf9d44d124071a936556bb61e2ccb